Sibylline & AI

Sibylline has been supporting it’s clients in the design and usage of AI models across a multitude of business verticals and befittingly we wanted to share how we think about the emerging trends and patterns in the sector much like our other work.
It might seem almost cliché to be jumping on the AI bandwagon like so many others, but our partners have been building and shipping AI products back when good GPT models were in their infancy, and more than a year before the introduction of the ChatGPT product that popularised them.
Introduction
When we talk about the most recent advances in AI, they come across in 2 key main verticals;
- Diffusion Models - such as DALL-E and Mid Journey
- Large Language Models (LLMs) - Models such as GPT-4 and LLAMA
Whilst there have been incredible advances in the generative AI section, especially across theoretical sectors such as healthcare and neuroscience, our work is mostly focussed around the use and deployment of LLMs and natural language, and and is where this series will keep its focus.
But what exactly are LLMs and natural language? This passage from a soon to be released white-paper we authored for a client explains;
Natural Language
Natural language refers to the ways humans communicate using either spoken or written words and naturally arises in human societies as a means of communication. Most of the languages we speak on this planet fall under the umbrella of “natural language”.
Natural language is both complex and flexible, and allows us humans to express a wide range of ideas, emotions, and concepts, but it’s also innately ambiguous. It’s this ambiguity that computers struggle to understand, and where the field of natural language processing comes in. There are no fixed rules in natural language, and even if there were, a significant portion of the speaking population would not follow them; this is the origin of slang and local dialects.
Natural language processing instead turned to the world of statistics to glean insight into language and how to make it machine usable, with the most recent breakthrough in this field coming in the form of “Large Language Models”
Large Language Model
Large Language Models (LLMs) are a form of artificial intelligence built on top of deep learning architectures, initially such as Neural Networks, but more recently leveraging what are called “Transformer” models, an approach initially pioneered by Google
LLMs were popularised by OpenAI with their release of the ChatGPT product; a simple interface for conversing with their latest GPT3.5 LLM model. This model surpassed all models at the time at the tests available, and captured the imagination of the world as it demonstrated the real power of LLMs in action, producing some incredible works of writing, code, and insight with what seemed like trivial effort
In practice, this model was simply the industrial application of natural language processing. The contextual meaning of sentences being passed to it, and the expected reply to them, was understood and created through the intensive statistical analysis of a massive dataset on machine learning models with billions of parameters.
Natural Translators
LLMs are exceptionally good at getting from one form of language to another, be it from one interpretation of a text to another, between whole other languages, or where some of the most important advances are being made, getting from language that people understand, to one that machines do.
The process of getting from what users want to do in software to the machines actually doing it has been one of the most important and studied fields in modern software engineering. It drives everything from the foundational APIs and primitives we build upon, to the user interfaces and design choices that are made.
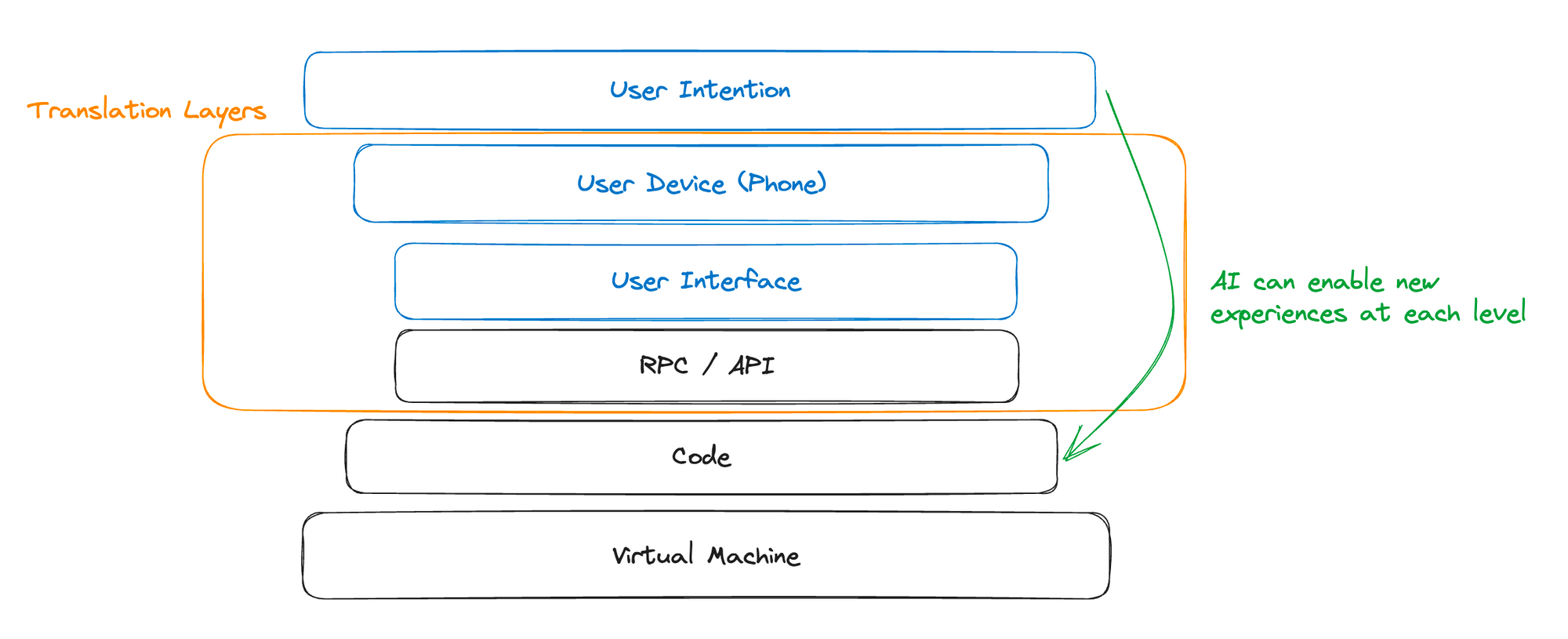
LLMs in this regard, are the translators we've always been looking for to help get us from the language of expressiveness and nuance that we humans use every day, to the language of rules that is necessary for computers to function.
There’s no clearer example of this than Github Copilot, a product designed to support engineers in writing code — the language of rules that machines are governed by — from simple human readable comments.
Prompt Machines
The use of LLMs is not however, just limited to translation. These models similarly fall under the "generative AI" banner for a reason; when given a limited input, prompt, or question, you can leverage them to generate or complete the content or answer for you. This enables them to fill interesting roles in the search and chat functions.
There's a common misconception around models such as these that they're sat atop some massive database of all known knowledge to answer questions, much in the same way a normal search engine is. This isn't quite accurate (albeit yes the new Bing and Bard products to leverage AI with their traditional search engine databases). These models are trained on massive datasets that allow them to predict the answer – with incredible accuracy – to your question.
Sibylline was named after the Sibylline books, ancient books purchased from a Sibyl by the last king of Rome, and consulted upon during times of great crisis. The word Sibyl is derived from the ancient greek sibylla or prohpetess; those who would give answers towards those who provide good questions.
LLMs operate on a similar premise. The responses that these models create are formed from not just the input question that you provide, but also from the surrounding context, additional input information, and "prompting". All of these collectively go in to draw the attention of the model to the next correct token, leading to the most accurate answer.
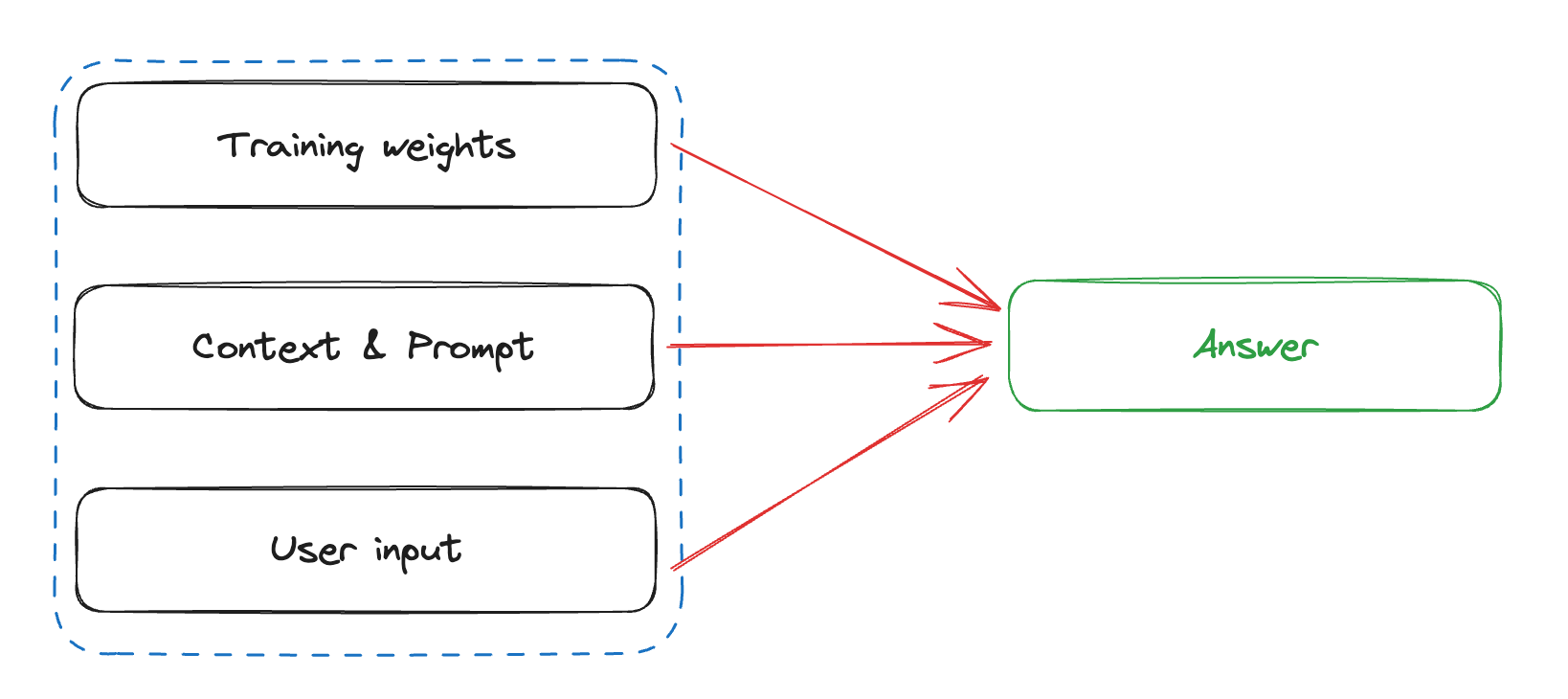
Or as Stephen Wolfram succinctly put it
Closing
The AI industry is advancing at a rapid pace, with innovations being unveiled so quickly it seems we might need our own platform to keep pace—an idea proposed internally and echoed by our clients.
As mentioned, this is the first in a series of posts about our work and experiments in the AI domain and how we guide clients in harnessing its potential. Throughout this series, we'll delve into:
- Our strategy for identifying and validating effective AI use-cases and deployments to address real client problems, and avoiding hype-driven investments
- Technical breakdowns of how we build and deploy cost-effective LLM solutions for our internal tools and projects
- Stories from our journeys with clients, highlighting the process of unlocking the power of AI for their businesses
Look forwards to having you follow us for the ride!